Norns - AI As Tools and Helpers in Writing
When I wrote the Fifth Anomaly, I came to the brutal realization that writing it, paying an editor, and then implementing those changes was just the beginning. I started building Norns as a way to minimize a lot of those later friction points for authors leveraging AI in a way that:
- It accommodates your writing style as an author, not forces you into its mindset
- It leverages AI to accomplish specialty or difficult and toil-laden tasks
- The AI agent is always there for you to interact with
- Critiques
- Writing Help
- Consistency
But the AI isn’t necessary. Norns implements a blob storage model for all of its content. That gives you versioning in platform, the ability to restore to a given version, and base formatting in the free tier when it launches. Since there’s no AI component, it’s not an expensive set of resources to offer. So you’ll be able to do best-effort EPUB / PDF generation without any cost.
Core Features (Not AI)
Bible
The bible is not constrained to a book. We have a higher level object that includes a series. The series can have its own bible and books can have their own bible. One of Norn’s biggest objectives is to minimize churn for actually managing these by capturing and updating at inflection points
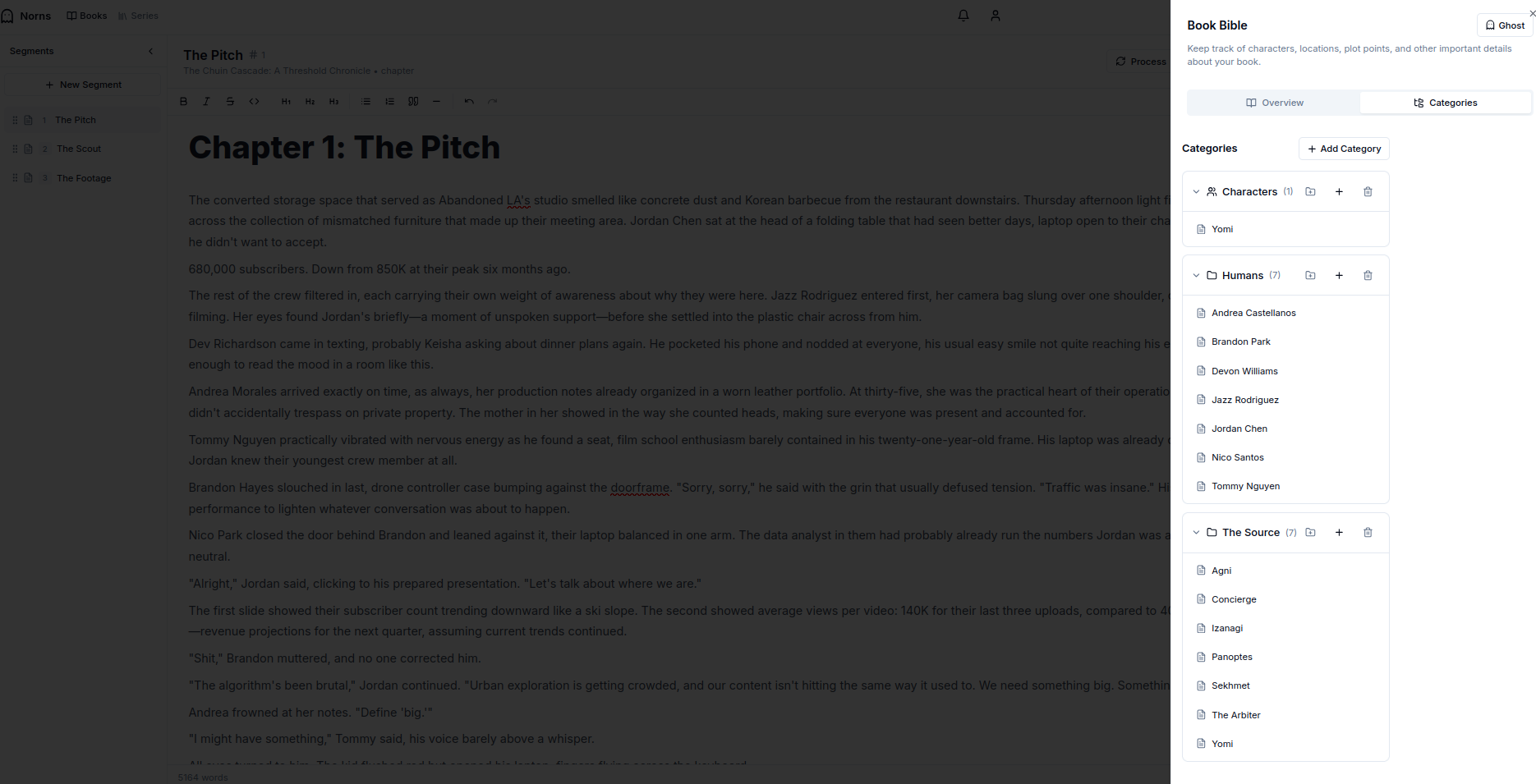
Segments
We use a general term called “segments” but these can be typed into “Chapters” or “Scenes”. You can then freely arrange and nest them in the layout
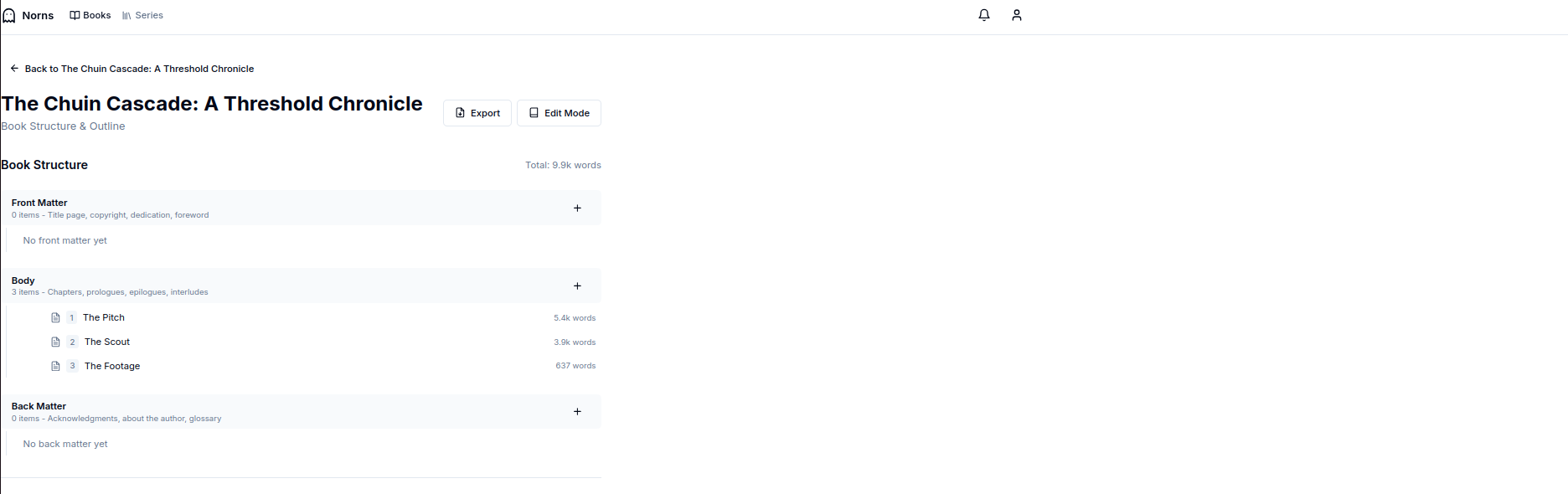
This essentially is the order in which we will stitch them together at the point of generation for formatting. It makes more sense to let the user decide exactly how this works. Some people also prefer to write in more granular pieces such as scenes, while some (like me) prefer a larger component such as a chapter.
Editor and History
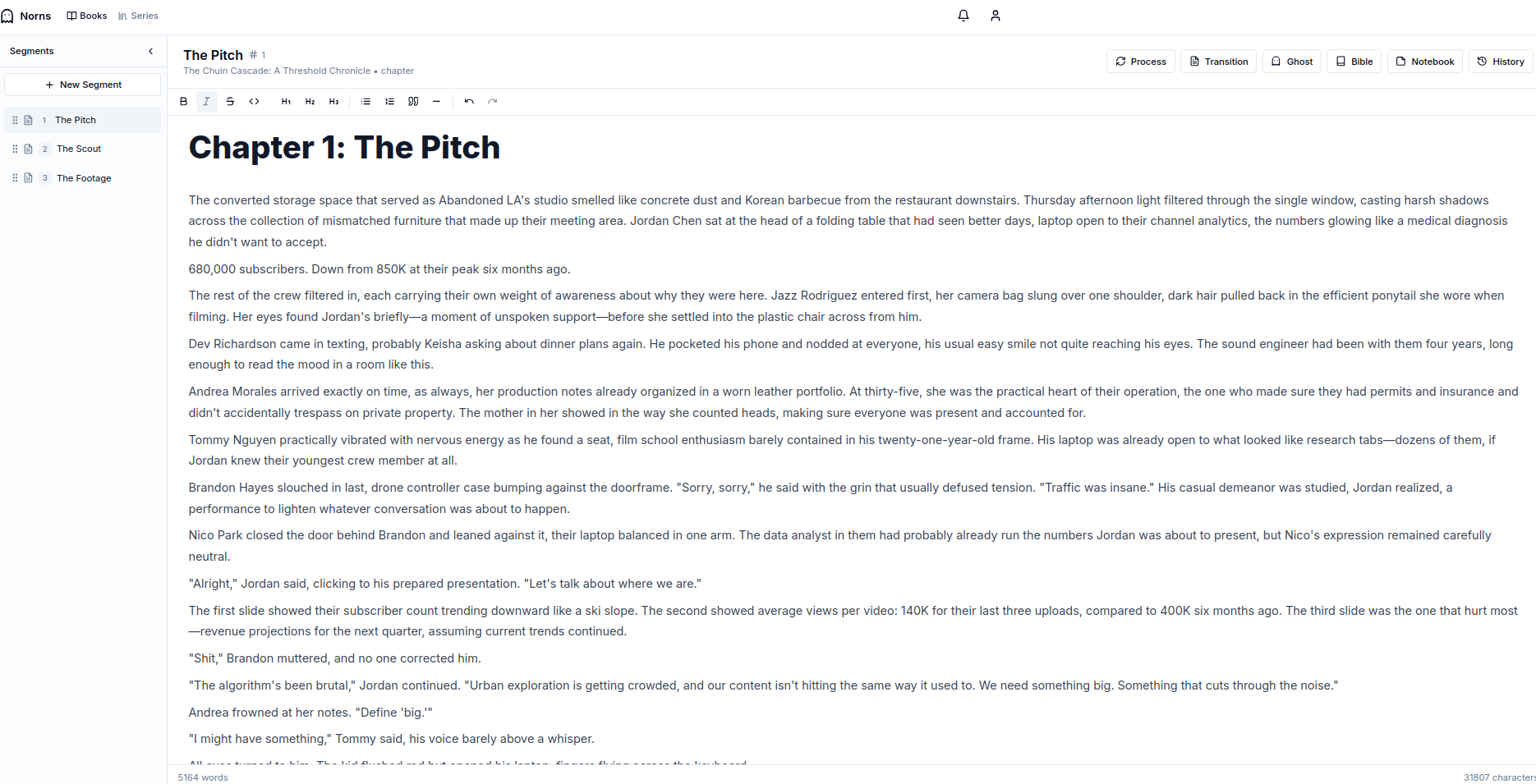
The segment editor (and all editors) are WYSIWYG editors built around markdown. It’s plain text. Easy to operate on and easy to export. Word’s doc format is literally an XML DOM under the hood and may seem easier to work with but you’ve got generations of that format with forked approaches and opinions to what in the end is a rich text file.
We treat all of these as discrete blobs in an object store which is versioned. The benefit is a baked in history you have available to you. Don’t like how things look, but remember a version you preferred? Find it and restore it
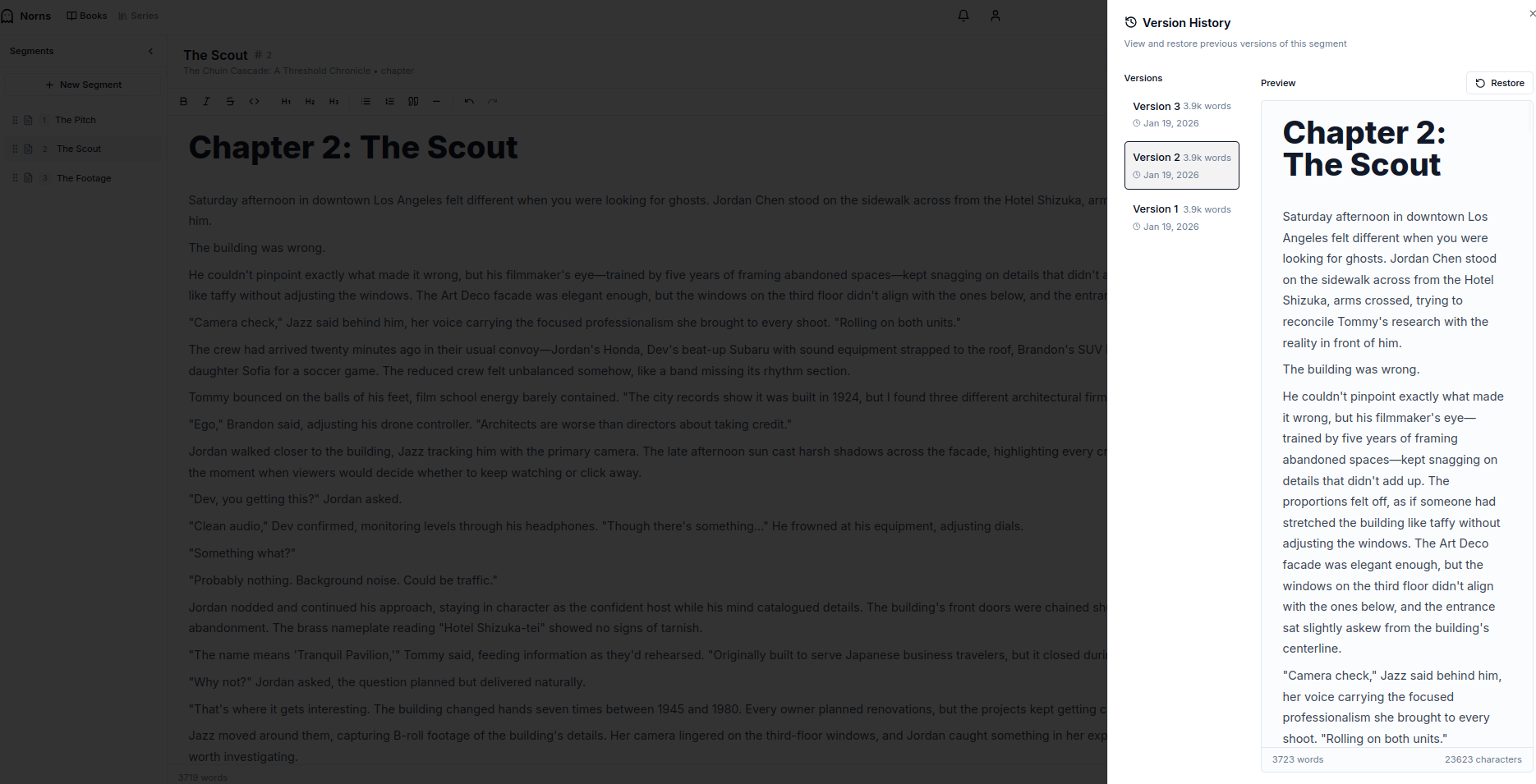
Notes
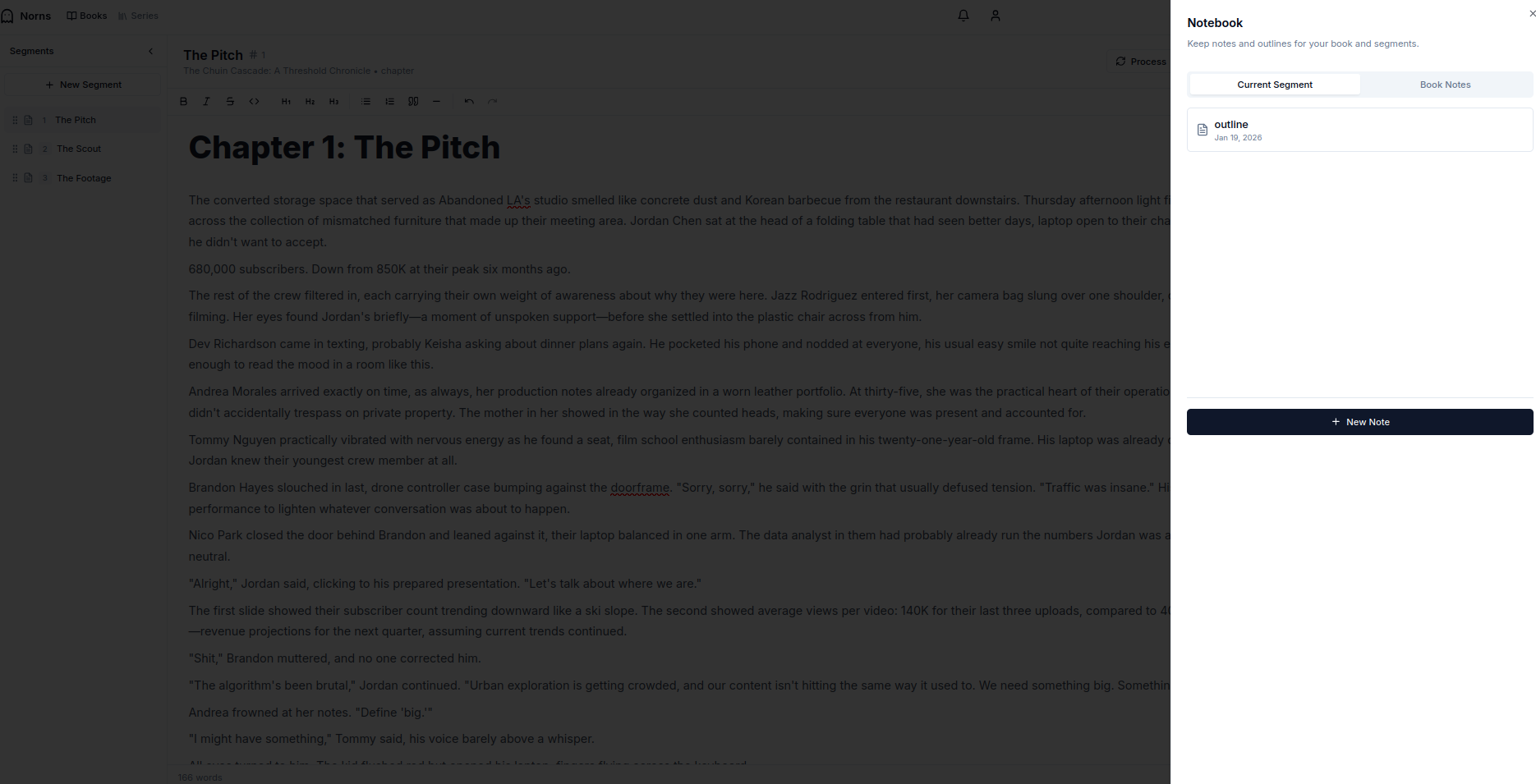
The bible and storyform are shape stores. The segments are a content store. Then what about metadata? Thoughts the author may have on scene that may or may not be part of it? Each segment has a notebook option which allows you to add any number of notes (however structured or unstructured as you want). These are also useful because they can be made available to the AI Agent later for ingestion.
Now that we’ve got an idea of the core tools available to the user to write with, let’s dig into the AI, its guiding philosophy and how to leverage it.
The AI’s Purpose and Presence
When we talk about AI in writing, we have a bad tendency to focus on “the vending” machine mental model. Put prompt in, get prose. While that works for some people, it’s notoriously bad at longform writing. The amount of articles you’ll find on “here’s how we score generated stories” on reddit is kind of dense. There’s a lot of discussion about “The models will naturally want to build this kind of ending…” and how all the stories feel the “same”.
The goal here is that it’s the human that drives everything. Maybe they write 30k words and then get stuck. You can provide your written content to the agent as context and ask “What are some options we have from here?”. So Norns sees AI as a “tool” rather than a production facility. In that sense, there are a few domains I’d like to dive deeper into:
Dramatica Theory
Let’s be honest. Dramatica theory is one of those things that feels appropriate for academics and those who make content for large story factories like Disney. Why? It’s a beast you have to care for and feed. Provide it structure up front, update it as you go and directions change, and for a lot of people that’s just not how they operate.
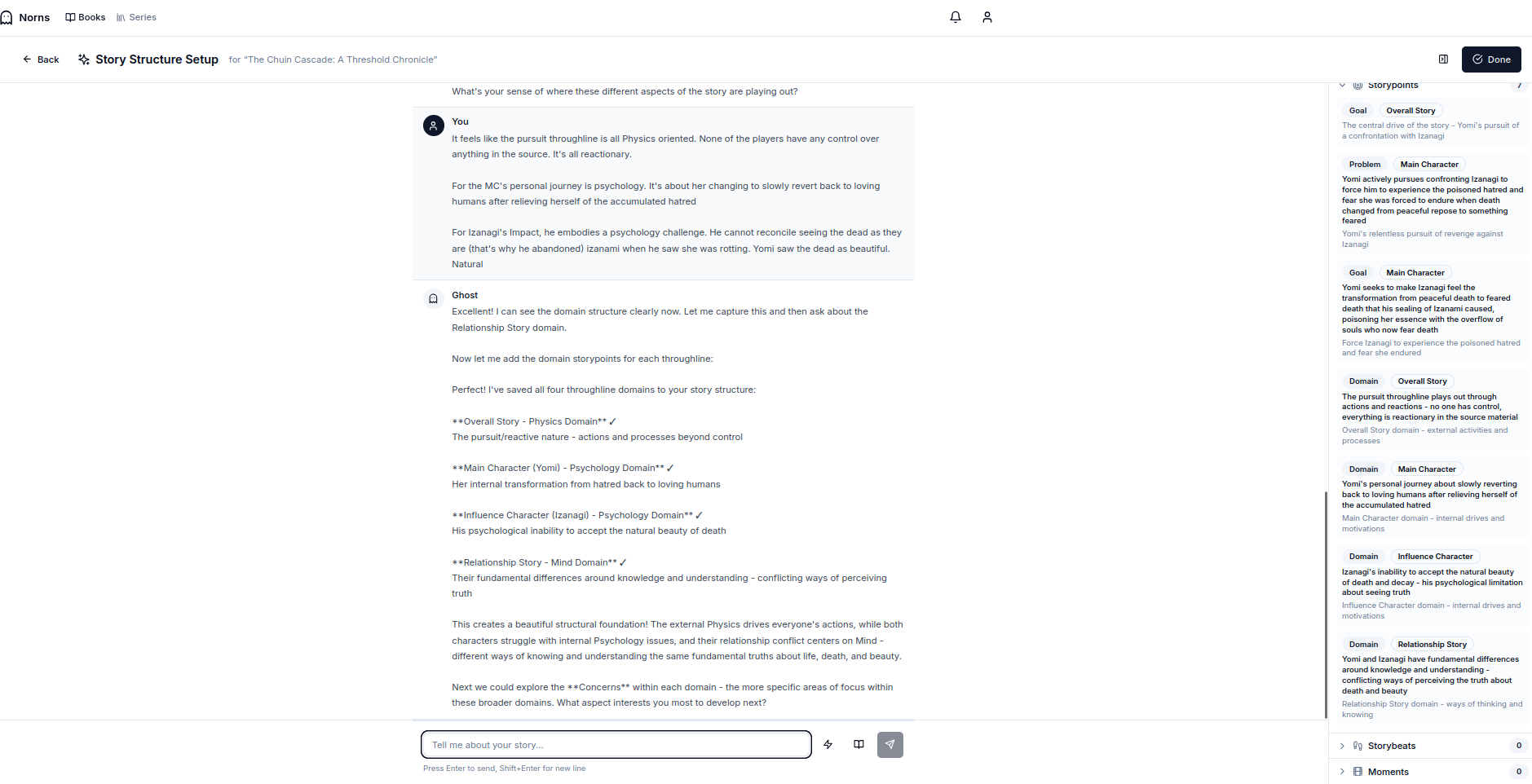
We take a different approach. Storyform is expressed to the agent (and externally) via an MCP server that expects a JWT in its request. It’s how we bound what it can / cannot access. A custom agent is accessible (at any time) but normally right when you create a new book. The goal is to have a conversation about the story and let the agent do the difficult work of translating that into storyform resources and creating / updating them.
That’s only half of the battle though. Most creatives are linear, pulled along by the story as the story happens or as flashes of inspiration hits. So we introduced the idea of delta processing.
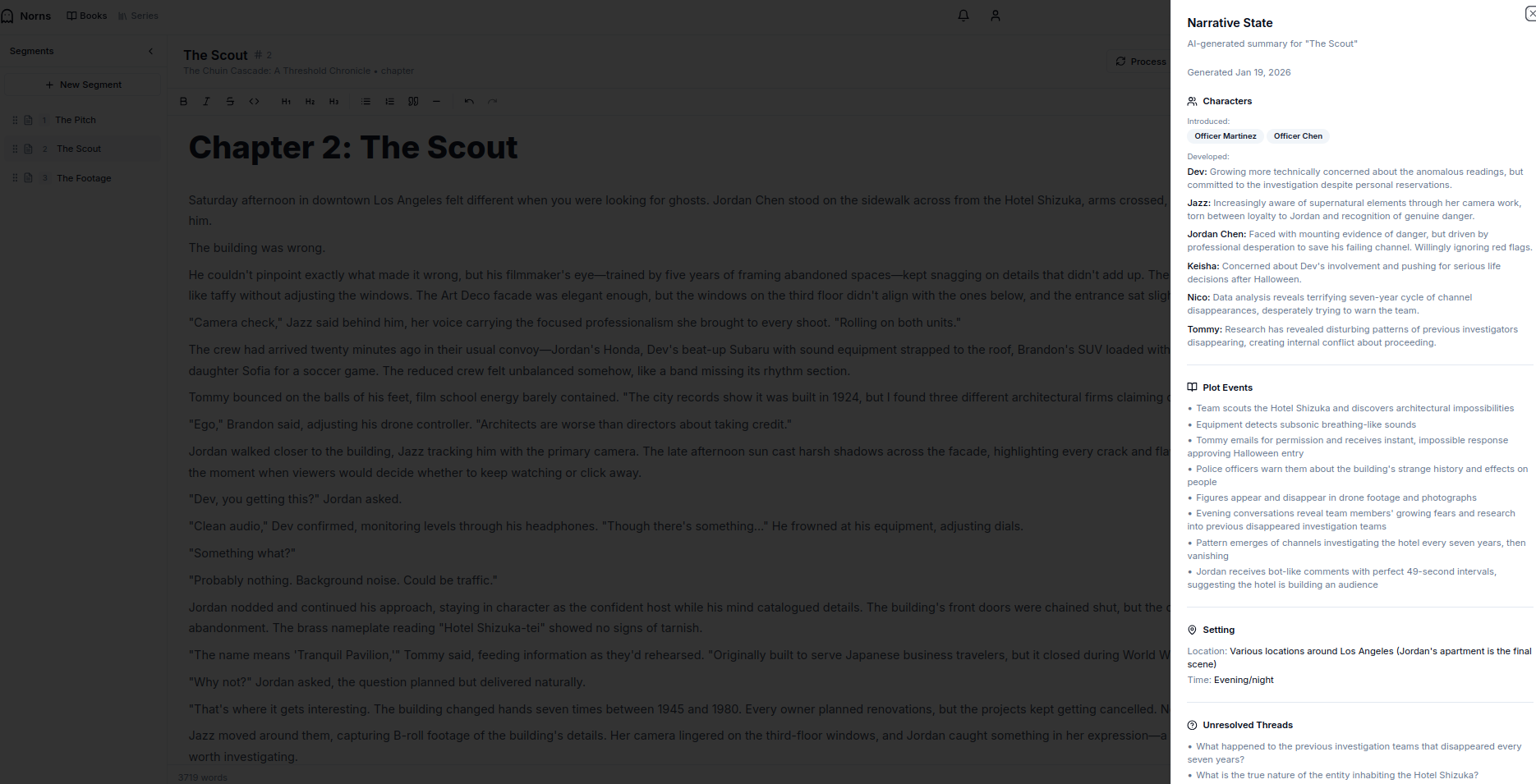
Basically when you say you’re ‘done enough’ with a given chapter, you can click this button and agents extract and catalog your chapter content:
- Characters: New introductions, development, interactions
- Plot Events: Key story beats and progression
- Setting: Locations and atmospheric details
- Unresolved Threads: Questions raised that need payoff
- Storyform Validation: Checks against declared throughlines and character arcs
Bible data is automatically adjusted, but notifications for users are provided if there’s a deviation from previously created throughlines in the storyform, or deviations from character progression as defined in the story form. The user can then choose to dismiss it or then go update the chapter (or even have the AI propose a change for them)
This makes the tedium of managing these resources mostly nonexistent. It’s also directional, as we store mathematical (vector) representations of this in the DB and expose MCP tools to the agent to allow it to search for content in the store more directly. Means less going back to source data (which is large and token dense) and more of the linear progression of the story and its objects.
The Payoff
Why bother with dramatica theory at all? Well imagine you’ve told yourself that you’re done with the story. You’re ready to go find an editor and drop $1K plus on getting a third party to read your creation. Are you ready? Is it?
What if you could ask an assistant to read through it, your notes, your plan, bible and give you an idea of how ready you are? That’s essentially what you’re capable of now. This is still a feature we need to build, but the goal is just like when you say you’re done with a segment, you can do a evaluation of the book at the end.
This is meant to be a tripartate perspective, and it will be the most expensive AI operation you can do.
Urd (What Has Been Written) The uninformed reader perspective. Reads only the manuscript.
- Does this land emotionally without external context?
- What assumptions are you making that didn’t make it to the page?
- Where is the reader confused or wanting more?
Verdandi (What Is Becoming) The structural architect. Reads manuscript against storyform.
- Does this implement your declared Dramatica structure?
- Are throughlines progressing at appropriate density?
- Is the crucial element present and resolved?
Skuld (What Shall Compound) The voice guardian. Reads for patterns and consistency.
- Character voice drift across chapters
- Overused phrases/constructions
- Emotional anchoring vs. exposition ratio
- Language patterns that will damage future installments
The goal is to get three perspectives of completeness, with one being very tied to the dramatica perspective. You’re looking for feedback like “We defined this a throughline, but there’s no termination of this storypoint”
After that you can make a decision whether or not you want to hand it off to an editor with some degree of comfort. To me this is analogous to having a suite of end-to-end tests for a product before putting it in someone’s hands.
Formatting
If you think writing the book is hard, wait until you have to actually get it formatted for print. Maybe other people’s writing won’t be as difficult as mine was, but I had a tremendous amount of heartburn in this space, namely because I deal with character sets that are non western, fenced styling, and a lot more edge cases.
It was painful. Weeks of cycling back to lua scripts for mapping byte codes of specific characters to fonts for latek. And this is a specific intersection I specialize in as a software engineer. For a person just trying to externalize a story, however it could be absolute agony. It’s why there’s markets of people who will format your book for the right price.
I took the model I used for my book and condensed it into a tight, agentic loop. The players are as follows:
- The Executor : Tries to execute a given plan for EPUB / PDF generation
- The Extractor : Takes the resultant artifacts and moves them into a temporary location
- The Verifier: Takes any user based rules and rules derived from the target (PDF for KDP or PDF for Ingram etc) and verifies the outputs
- The Troubleshooter: If execution fails, or validation fails, this agents job is to reconcile why and provide a new plan for the Executor to enact
This basically goes through a number of loops and once the troubleshooter produces a plan that creates artifacts that pass validation the problem statement, resolution and proof are provided into a knowledge base and vectorized. This means that it’s expensive to operate up front from a platform perspective, but the more it runs, the more it relies on finding known fixes up front and applying those in the first round.
Guard Rails and Controls - The Validation Agent
While not everyone will write this way, some people will want to leverage the AI for generation of the content itself. That’s totally fine, but there’s a lot of considerations when doing that.
As mentioned in the beginning, a lot of people write about the LLM’s tendency to write X or Y.
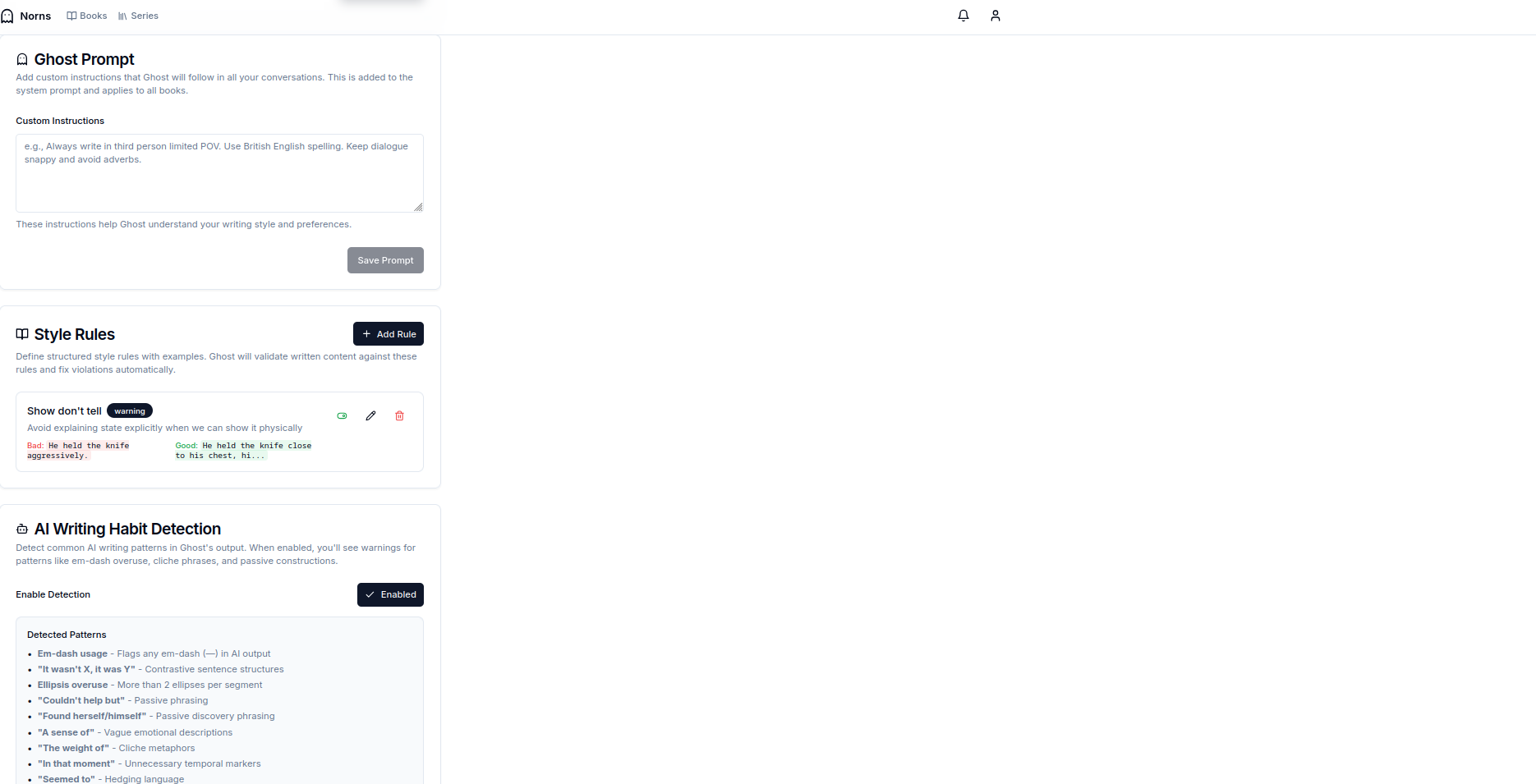
One thing we added is the ability to define user level pattern definitions. These allow the user to define a pattern with a bad example and a preferred form of that expression. There’s also a checkbox for “catching AI writing tics”. These are leveraged by the validation agent.
A lot of what you’ll find online is about prompt tricks to get the AI to write a certain way. The fundamental truth is that the larger your context, the less you get attention paid to anything in the middle, and it’s less space to actually perform logic / reasoning. So we took the approach of “Let it generate a thing” and that triggers an automatic validation. It returns requests to change back to the agent, who confirms “Oh I have to fix these” and begins to make and apply those changes.
As opposed to assuming a prompt will solve the problem, we use a different tool for that problem space altogether.
Inherited Prompts
Users, Series, and Individual books can also have their own prompt written by the user. This will allow an inherited prompt that is concatenated onto the system prompt to drive how your interacts with ghost go. This is useful if you prefer a “nuts and bolts, no frill” agent. Just tell it to be succint and to the point.
Conclusion
Norns isn’t available for public consumption yet. I’m using it to essentially run through my second book again and see how it affects my process. More features will get added, but it’s going to get dogfooded against my own expectations before anyone else gets to play with it.
Here is a list of currently planned features still being implemented:
- Tripartate panel evaluation of completion
- Author Assistance and Tooling
- Build and distribute reader magnets from Norns
- Build and manage ARC Campaigns from Norns
- Possible integrations with Booksirens / BookBounty etc.
- Author Blogs as part of Norns
- Email List management in Norns
- KDP Advertising Management in Norns
- Agentic management and summary of KDP advertising with Amazon